
Here we are again! In the previous post of this series I have begun recapping my learning path in QC, with the aim of sharing useful assets, since early readings in 2016 to recent brush-up, and hints. We have spoken about skills I feel necessary to avoid preliminaries coming from many STEM fields, and introduced seminal stuff to approach QC (remember: seminal is not a byword for easy).
Today we are going to deal with a more technical topic representing nowadays main issue to get an useful quantum computing: error correction. (Disclaimer: I’m going to stick to original idea of offering a learning path based on already publicly available resources without proposing any other original contents from mine, but in this post sometimes I’ll have to get to the heart of the matter)
“Wait! You said “issue”! Do you mean we still haven’t a working QC, after 10 years since IBM making its first version cloud-available? So why to read this boring series NOW?”
ANSWERS:
- not yet, and there are very different ideas out there about when it will happen (that’s why in the first post I wrote about working hard without taking any easy target for granted). Someone also doubts it will ever happen, but honestly I believe the existence of initiatives like NIST PQC Standardization represents a qualified opinion that it’s only a matter of time;
- a lot of things have happened in the last years, both theoretical and industrial research, culminating in many different ways to build qubits (not only superconductive ones like IBM’s) and improvements on algorithms: in the last part of the previous post we have already seen how wide the landscape is, and it’s worth noticing that Google’s recent work on Shor implementation (reducing the needed gates/qubits) has been made available only as a ZKP, implicitly qualifying the improvement as industrial secret (or more?)
So let’s speak of QEC (Quantum Error Correction). Noise is very noisy ;) for QC: measurements collapse the state and almost every non-strictly-controlled interaction can be considered a measurement, so it’s very easy to break the system of qubits you are been using via gates to implement your algo. And the most studied QC type, the superconductive one, has to work near absolute 0 temperature making the scenario even harder to handle: using one sentence, we can say any environment interaction is a problem. More, gates can introduce errors as well, being actual devices often needing calibration and “living” in the world of what is technologically feasible rather than in components’ ideal behaviours one.
Like in classical telecommunications the error handling still relies on redundancy: given a system prone to issues, replicate parts where errors nest (the qubits in our case) so that multiple copies permit to identify (and hopefully correct) the wrong one(s); and all of that without widening too much the size of what can accomodate errors: this trade-off is codes’ magic.
Nowadays there are two main code families:
- Surface codes: quite well established and consolidated, with a lot of papers dealing with many aspects of their use, they enforce a planar “locality-preserving” structure where each qubit has to interact only with nearest neighbours ones: this property greatly fits with planar design of supercomputing QCs, at the expense of quite big redundancy to be introduced;
- qLDPC (quantum Low-Density Parity-Check) codes: based on the generalization of the framework Surface codes are built upon, they are are the new guys in town, still cutting-edge research. They reduce the needed redundancy given a target performance, at the cost of relaxing the locality “orthodoxy”: even more distant (than nearest neighbours) qubits have to interact, which seems to be feasible for a new type of QC, the neutral atoms one (probably it’s no accident that Google has begun investing on that even if not abandoning the traditional superconductive path).
I have thought about it quite a while: I believe the best way to gain knowledge of Surface codes avoiding to initially read a lot of papers (each with its own conventions, often hard to reconcile for a rookie) is to deal, in an “interleaved” way, with two resources:
- The Hitchhiker’s Guide to the Surface Code paper by Fang Zhang and Jianxin Chen (https://doi.org/10.3390/e28020251);
- Arthur Pesah’s Blog posts.
The first is a very dense paper giving an overall taste of almost all the field, challenging to be read but rewarding with hints of deeper aspects if you work hard and go beyond casual reading (remember, LLMs are your best friends dealing with these well consolidated topics); the second -being a blog- lacks completeness and overall is less self-contained in fact preferring a certain amount of freedom in post contents (even if concepts are explained in a gradual way) but it’s very didactic, proceeding at a slow pace and proposing reinforcing exercises.
Imho you should follow this reading path:
- 1: post All you need to know about classical error correction;
- 2: post The stabilizer trilogy I — Stabilizer codes;
- 3: post The stabilizer trilogy II — Logical operators;
I avoided to suggest first blog post on the topic (A bird’s-eye view of quantum error correction and fault tolerance) because it touches a lot of topics but of course without explaining any: imho it’s better to read it as a sort of sanity check in the end, as a recap. Stabilizers and logical operators explanations clarify a lot of stuff that in Hitchhiker’s Guide is just introduced leaving the reader the task to deepen: for sure struggling on them could be very instructive, but maybe a it’s a bit “too much” if groups-theory isn’t your daily meal.
- 4: first 21 pages of Hitchhiker’s Guide (till Defect diagram, not included);
when you’ll see non-destructive stabilizers measurements you should recognize parity measurements circuits met in IBM Quantum Experience Documentation (so Pesah’s posts don’t link the two concepts by chance). Surface codes’ logical operator row-like and column-like natures are almost not justified, just referred to repetition codes ones: take that for granted, later on you’ll meet explanation.
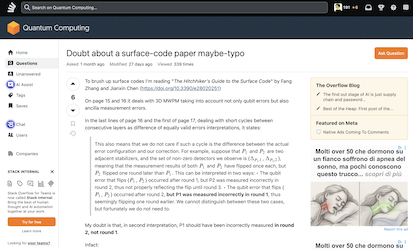
Where this paper imho excels is decoding and fault tolerance introduction: it relates minimum-weight decoder with graph Minimum-Weight Perfect Matching; offers coarse but convincing threshold estimate; introduces measurement errors handling substituting stabilizers with detectors in decoding graph (and extending it from 2D to 3D): working to understand deeply of all this, maybe sketching some graphs by hands, is worth the effort. A hint, because it could be not so easy to recognize it while learning: at page 17 there’s a typo affecting a concept, I have documented it in a quantumcomputing.stackexchange.com Q&A.
Coming back to Hitchhiker’s Guide, surface codes actual stabilizer measurement circuits and circuit-level error model at pages 19-21 offer a glimpse at how all this stuff looks when implementing it; handling decoding time-boundaries (aka initialization and logical measurement) at pages 17-18 show embedding and removing of items into/from the code, useful in the last part of the learning path dealing with lattice surgery.
Of course a 35 pages paper has to choose what to omit: in our case the biggest miss is unrotated surface codes, however you can find them and how they relate to paper’s rotated one in the next Pesah’s post to be read:
it’s an interactive post, enforcing a code visualizer co-developed by the author, which also has an independent life as a playground (https://gui.quantumcodes.io). In this post you’ll also find the explanation about why logical operator are row-like and column-like and a recap of the error models (code-capacity/phenomenological/circuit-level) and threshold values already met in the paper. Then it’s time to dig in defect diagram and lattice surgery:
- 6: pages 21-26 of Hitchhiker’s Guide
My suggestion while studying defect diagram and ways to shape it is never forget that it’s a decoding graph with detectors as vertices, because it’s always a matter of activating or switching off stabilizers during time evolution (regarding that please note: that it’s why earlier I mentioned initialization and logical measurement as useful for this stuff as well; and that stabilizers huge role shouldn’t be a surprise at this point, given they born as constraint to keep code well formed, even during code evolution in the case of lattice surgery).
In this part the paper miss to explicit define Pauli frame updates, in fact preferring to speak of generic “necessary adjustments”: you can help yourself about that with ChatGPT, discovering it’s just a way to track intermediate results classically during elaboration till final algorithm output.
I also want to spend some hints about S-shaped defect diagram as teleportation (page 25) because speaking of S shape could mislead the reader into considering time as flowing along the shape, influenced by how we write S by hand: in fact in defect diagrams (and this does not make an exception) time flows from left to right, and the shape of the diagram is just a topological equivalent of gates. So, the upper part of S (the C part) is equivalent to Bell states creation, with the two entangled qubits “exiting” from that part of the tube via the two ends of the C, one in the top right, the other in the bottom right; the lower part of the S (the mirrored-C part) is equivalent to Bell measurement by teleportation sender, taking as input one of the two entangled qubits produced earlier (ingested where C and mirrored-C touch each other: bottom right of C and top left of mirrored-C) and the state to teleport (ingested via bottom left of mirrored-C). What does we still miss? The top right of the C part, the second entangled qubit, the one owned by teleportation recipient: correcting it by means of ALL Pauli frame updates we have collected during time evolution we’ll get the teleported state.
I have detailed all of this because I believe lattice surgery is a very abstract part of the paper, where a recall to concreteness is helpful; and as an example of the kind of work it’s required to gain the most by studying.
Dealing with Hadamard, transversal gates are nominated, but I definitely prefer their explanation in a Pesah’s post:
In the post there’s also the Pesah’s coverage of how gates relates to stabilizers and how they transform Pauli operators: given you have already read about it at page 7 of Hitchhiker’s Guide, it’s a good opportunity to recap the topic and check if everything is straightforward. Going back to transversal gates, non availability of S one on surface codes (and GENERAL non availability of S, at least without quite convoluted techniques) opens the chapter of ingestion and distillation: the post just introduces them, the paper spends more words:
- 8: last pages of Hitchhiker’s Guide
The problem is to find a way to implement gates not suitable for lattice “good” encodings: essentially non-Clifford ones: the idea is to state inject arbitrary states (not only stabilizer states, which are the ones considered till this point) because through gate teleportation they can be “converted” to an arbitrary gate (which one depends on the arbitrary beginning state, non-Clifford ones as well). But state injection is a not fault-tolerant procedure, hence you have to make many redundant copies of it: we know redundancy = code, so it means coding injected state in a suitable code (which is indeed nested into surface one). We’ll then be able to correct the noisy injected state (to be honest we don’t correct it, we just detect the noise and repeat the procedure till we get a no-noise case - it’s called post-selection): so we are distilling a noiseless non stabilizer state. Once got, we use teleportation to convert it to the corresponding non-Clifford gate (of course we chose the injected state to obtain exactly the desired gate).
As you have seen teleportation comes after distillation (and it makes sense, better to get a good state before using it), but paper at page 30 speaks about teleporting (point 2.) before decoding/distilling via post-selection (point 3.): however that is not the “effective” teleportation, in fact just a “service” one used to get redundant injected state after initializing nested code (point 1.)
Topologically playing with lattice is really cool, and it’s the cutting-edge development of surface code use: it would deserve a lot of tries-mistakes-learning iterations to be fully handled. An inspiring paper in that direction could be:
- 9: Lattice Surgery for Dummies by Avimita Chatterjee, Subrata Das, Swaroop Ghosh (arXiv:2404.13202v2)

A part from recapping many concepts and presenting “surgery version” of various gates, I found very interesting its point of view, given it doesn’t deal with defect diagrams preferring unrotated open-boundaries lattices: merging and splitting now implies adding data qubits, their kind depending on stabilizers introduced or removed by the surgery. It’s also a good unrotated lattice handling exercise, given the paper first image uses a different conventions compared to Pesah’s blog, then it switches to the same one, and one of the lattices has wrong logical operators: your homework to find which one! :)
I think that’s enough… maybe most careful readers have been noticing I haven’t suggested two (to date) remaining Arthur Pesah’s blog posts belonging to surface code series: The stabilizer trilogy III — Parity-check matrices and decoding and The topology of topological QEC I — Manifolds and complexes. They deal with stabilizers in the context of linear algebra (remember: we have seen them from the point of view of groups theory) and with deep math foundations of surface codes: even if they surely permit to strengthen knowledge, I see them more as a jump-start to a new world: so maybe they will be part of a future post of this series.
Bye! :)